Підрозділ 18.4
StreamReader та StreamWriter. Текстові потоки
18.4. StreamReader та StreamWriter. Текстові потоки FileStream із розділу 18.3 оперує байтами — він не знає нічого про текст, рядки, символи чи кодування. Якщо потрібно читати чи записувати текстові дані, щораз
18.4. StreamReader та StreamWriter. Текстові потоки
FileStream із розділу 18.3 оперує байтами — він не знає нічого про текст, рядки, символи чи кодування. Якщо потрібно читати чи записувати текстові дані, щоразу виконувати ручне кодування/декодування байтів незручно і ненадійно. Саме для цього .NET надає StreamReader і StreamWriter — текстові обгортки над потоком, що прозоро обробляють кодування символів і надають зручний рядковий API.
Ключовий принцип: StreamReader / StreamWriter не є самостійними — вони декорують інший Stream (найчастіше FileStream). Це класичний патерн Decorator: обгортка додає нову поведінку (роботу з текстом), не змінюючи базову абстракцію потоку.

StreamWriter — запис тексту у потік
StreamWriter перетворює рядки на байти з урахуванням кодування і записує їх у базовий потік.
Базовий запис
Другий параметр конструктора append: false — якщо true, файл відкривається у режимі дозапису. Фактично це визначає FileMode: false → FileMode.Create, true → FileMode.Append.
AutoFlush та буферизація
За замовчуванням AutoFlush = false — дані накопичуються у внутрішньому буфері (зазвичай 4 KB) і записуються на диск при заповненні буфера або при Flush()/Dispose(). Для журналів подій де критична надійність встановлюйте AutoFlush = true.
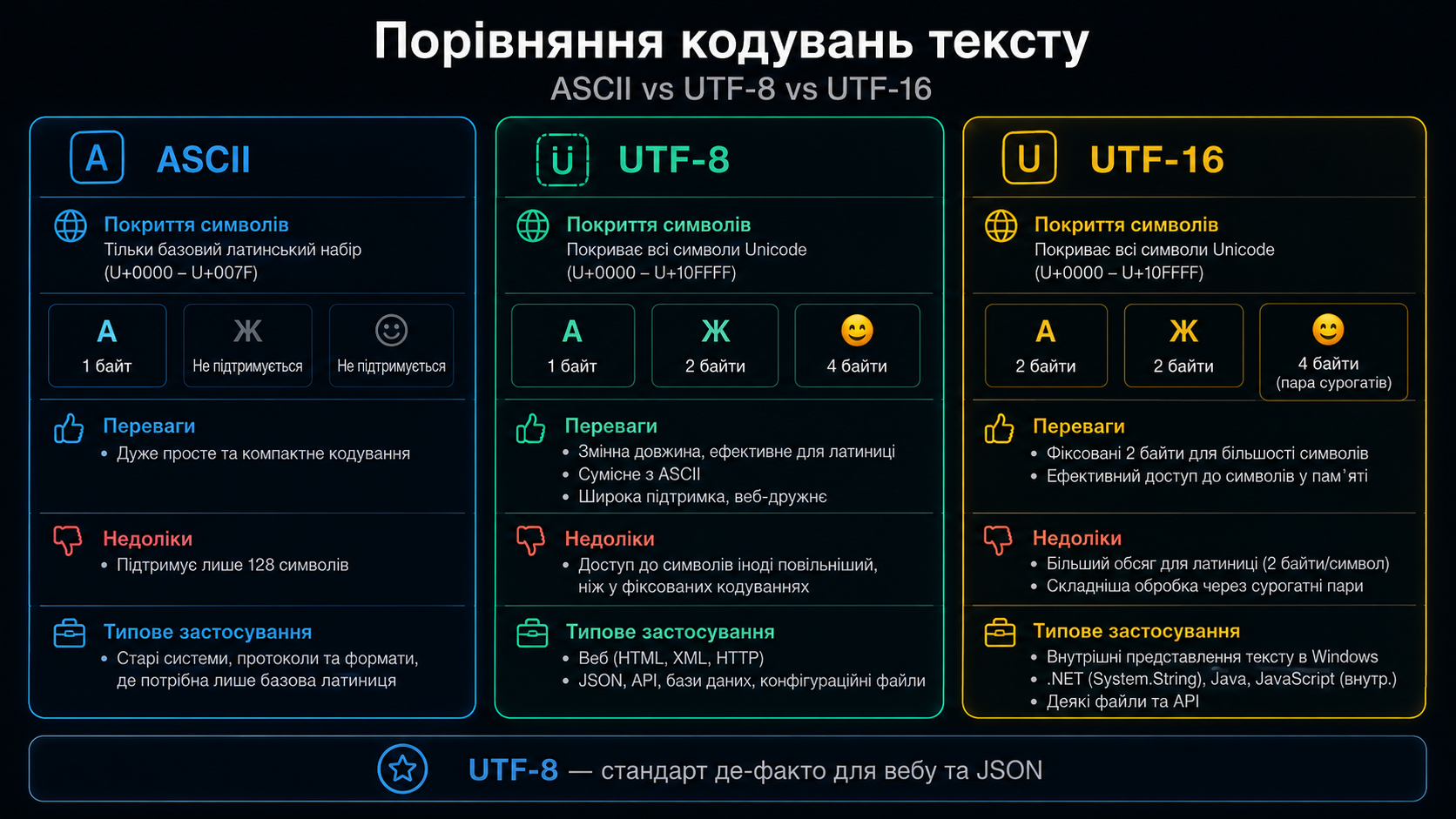
Кодування — як StreamWriter обробляє символи
Рекомендація для нових застосунків: завжди використовуйте Encoding.UTF8 — це стандарт де-факто для текстових файлів у сучасних системах. Encoding.UTF8 у .NET 5+ не додає BOM (Byte Order Mark) за замовчуванням, що сумісно з усіма платформами.
StreamReader — читання тексту з потоку
StreamReader декодує байти з базового потоку у символи рядків. Надає методи для читання рядок за рядком, символ за символом або весь вміст одразу.
Базове читання
Методи читання: ReadLine, Read, ReadToEnd, Peek
Peek() — без споживання символу. Це дозволяє перевірити, чи є ще дані, перш ніж читати: while (sr.Peek() != -1) { ... }. Повертає -1 на кінці потоку.
Обробка великих файлів рядок за рядком
ReadLine() — ідеальний вибір для обробки великих текстових файлів: тримає у пам'яті лише один рядок, обробляє гігабайтні файли без OutOfMemoryException.
StringReader та StringWriter — потоки над рядком
StringReader і StringWriter реалізують той самий текстовий інтерфейс, що StreamReader/StreamWriter, але над string або StringBuilder у пам'яті. Корисні для тестування та обробки рядкових даних без файлів:
TextReader і TextWriter — абстрактні базові класи для StreamReader/StringReader та StreamWriter/StringWriter відповідно. Код, написаний проти TextReader, однаково працює з файлом, рядком або будь-яким іншим текстовим джерелом.
Практичний сценарій: CSV-парсинг медичних записів